Compute‑Skalierung als dominanter Fortschrittstreiber
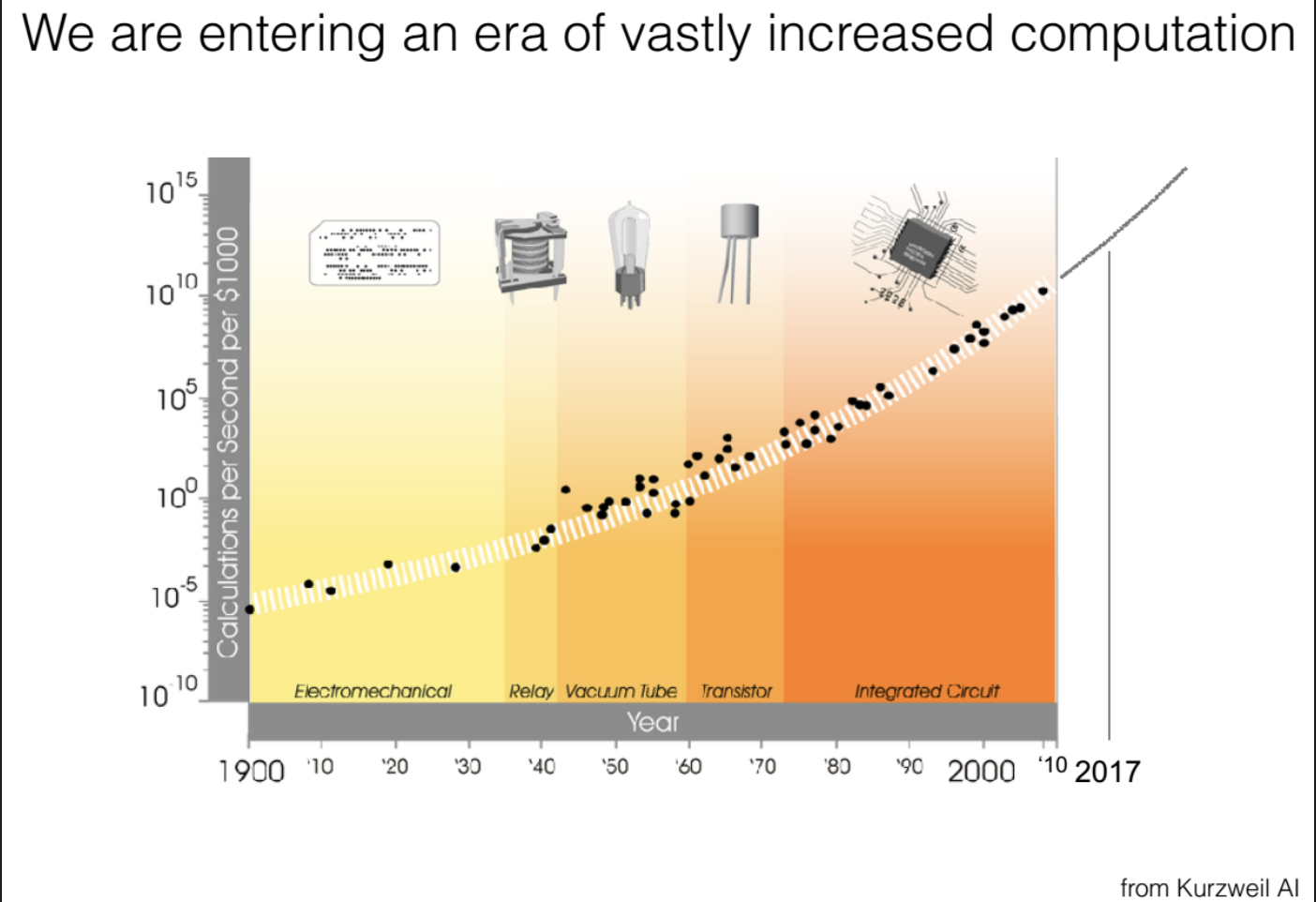
Abbildung 1: Dramatischer Anstieg der verfügbaren Rechenleistung im Laufe der Zeit (Y‑Achse log. Skala; X‑Achse Jahre). Exponentiell fallende Kosten pro Recheneinheit führen dazu, dass wir heute um Größenordnungen mehr Berechnungen pro Dollar durchführen können als noch vor wenigen Jahrzehnten.
Der beispiellose Aufstieg aktueller KI‑Systeme ist vor allem auf eines zurückzuführen: immer mehr und immer günstigere Rechenleistung. Hyung Won Chung (OpenAI) betonte in seinem Stanford‑Vortrag, dass exponentiell billigerer Compute und entsprechendes Skalieren der Modelle die primären Treiber des KI‑Fortschritts sind. Empirische Scaling Laws zeigen, dass sich die Leistung als Potenzgesetz mit Modellgröße, Datenmenge und Rechenaufwand verbessert, während Details der Architektur langfristig weniger zählen. Kurz: Mehr Daten und mehr FLOPs schlagen ausgefeilte Architekturen.
Diese Entwicklung spiegelt sich in Investitionen und Hardware wider (TSMC‑Fabs, GPU‑Boom, Supercomputer‑Programme). Compute ist zur zentralen Währung geworden – Ansätze, die mit steigender Rechenleistung immer besser skalieren, überflügeln andere.
Risiken überstrukturierter Modelle
Unter Modellstruktur verstehen wir von Menschen eingebaute Annahmen/Module/Regeln. Sie bringen oft kurzfristige Vorteile, skalieren aber häufig nicht, wenn Compute stark wächst. Rich Suttons Bittere Lektion (2019): Generalistische Methoden, die massiv Rechenpower nutzen, schlagen spezialisierte Ansätze auf lange Sicht. Beispiele wie maschinelle Übersetzung zeigen, wie einfache, große Transformer die vormals „smarten“ Spezialarchitekturen ablösten.
Weniger Struktur, mehr Compute: strategisch richtig
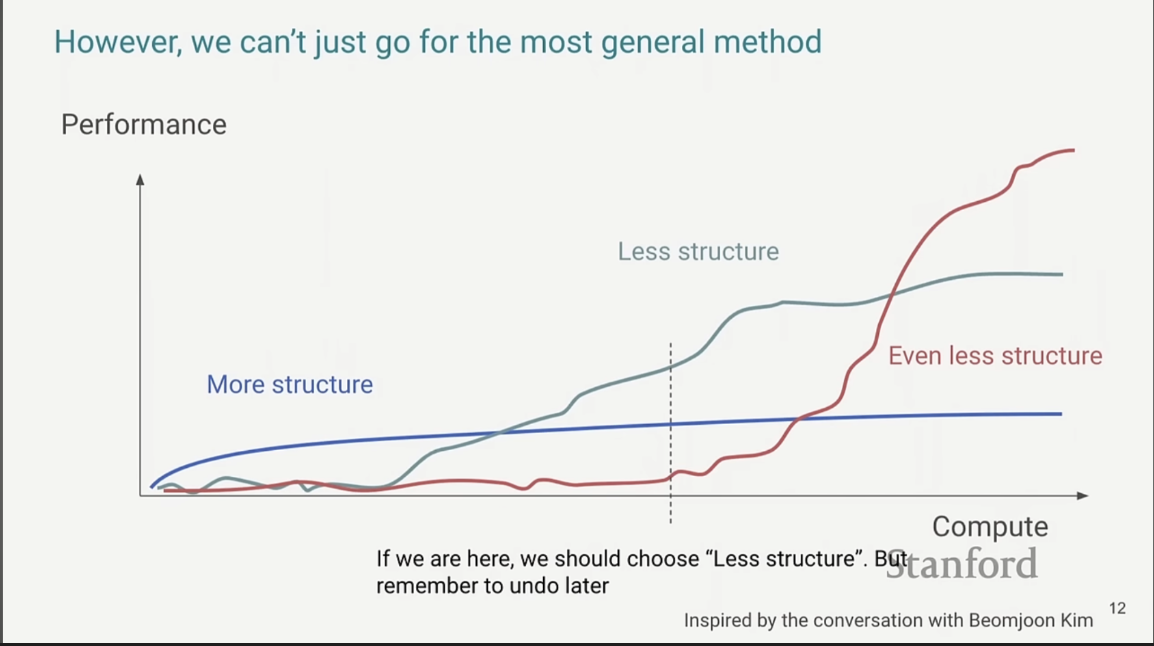
Abbildung 2: Schematische Performance unterschiedlicher Ansätze in Abhängigkeit vom Compute‑Budget. Anfangs dominiert „mehr Struktur“ (blau), später skaliert „weniger Struktur“ (rot) steiler und überholt.
Chungs Kernaussage: Je näher wir an Compute‑Meilensteine kommen, desto eher sollten wir Struktur abbauen und generalistischere Methoden wählen – und frühere „Hilfskrücken“ konsequent entfernen („…remember to undo later.“).
Die „Bittere Lektion“ für Forschung & Praxis
Langfristig belohnt Rechenstärke generalistische Ansätze. Erfolgreiche Strategie: Methoden bauen, die mit +10× Compute besser werden – denn dieses +10× kommt. Investitionen in Compute sind damit Investitionen in diese Skalierungsfähigkeit.
Vortrag: Stanford CS25: V4 – Hyung Won Chung (OpenAI)
Weiterlesen: Rich Sutton – The Bitter Lesson